.png?table=collection&id=cb472e47-cf59-4081-bd5f-899a844344db&t=cb472e47-cf59-4081-bd5f-899a844344db)
type
Post
status
Published
date
Feb 28, 2025
slug
llm-8
summary
tags
RM
llm
category
LLM
icon
password
1. 训练 Reward 模型
(LLM 的老师,评判比生成的能力要简单很多)
假设已经做完了 SFT
1. 1 训练数据格式
- 输入example:把问答拼接在一起作为输入 {1. 什么是数据库?数据库用于存储数据,2.什么是数据库?数据库是一个有组织的数据集合,允许高效的数据存储、检索和管理}
- 输出example:一个得分值,可以使用 bert 或者 LLM。
一般来说 Reward 充当一个当老师的角色,所以Reward 模型的能力起码与要对齐的LLM 实力相当,甚至要更高一点。
评价回答的好坏会比生成回答容易的多,输出能力的提升,评价能力也会提升。
大模型能力的极限是由预训练决定的,强化学习只是让能力尽可能的逼近极限。
1.2. 改造现有的LLM
原生的 LLM 最后有一个 Linear 层
(hidden_size * vocab_size),这一层全部 token 共享,因为每一个 token 都需要预测下一个 token。
现在除了这个 Linear 层还要加一个 score head
(hidden_size * 1),只对序列的最后一个 token 调用 score head,因为只有最后一个token 能看到前面的所有序列,对前面的序列进行评分,得到Reward 值。

1.3. Reward 模型的 Loss
Reword 模型的训练数据集是一个问题对应着好和坏两个回答:
chosen 列中提供较好的信息,而在 rejected 列中提供较差的信息需要调用两次 Reward 模型,分别得到模型对
chosen 和 rejected 回答的得分,然后根据下面公式计算 Loss
当 chosen 的得分小于 rejected 的得分时,Loss 急剧上升,相反急速下降
2. PPO 模型的训练
2.1 训练数据
2.2 RLHF中的四个重要角色


如上图,在RLHF-PPO阶段,一共有四个主要模型,分别是:
- 基准模型(reference model),SFT之后的模型,作为策略约束的锚点,防止策略模型过度优化,
- 训练模型(策略模型)(Actor model), PPO训练的目标就是优化训练模型,负责生成响应。产出动作
- 奖励模型(Reward model),score head 只对最后一个token 有效,它的作用是计算即时收益
- 状态价值模型(Critic model)(state-value model ): 对每个状态评估其价值,也就是根据截止到目前的 token 序列,预测到序列结束生成后,这个问答序列的期望回报是多少。与Reward不同,它的 value head 对每一个token 都有效。它的作用是预估总收益
- Actor/Critic Model在RLHF阶段是需要训练的(图中给这两个模型加了粗边,就是表示这个含义);而Reward/Reference Model是参数冻结的。
- Critic/Reward/Reference Model共同组成了一个“奖励-loss”计算体系,我们综合它们的结果计算loss,用于更新Actor和Critic Model
2.2.1 Actor Model (演员模型)
Actor就是我们想要训练的目标语言模型。我们一般用SFT阶段产出的SFT模型来对它做初始化。
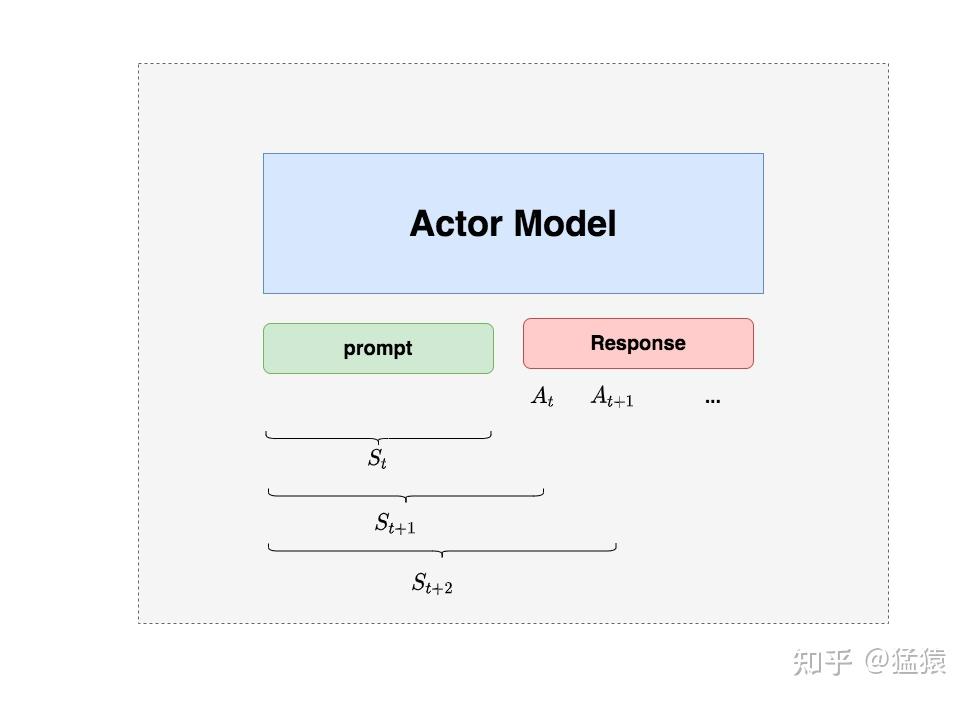
我们的最终目的是让Actor模型能产生符合人类喜好的response。
所以我们的策略是,先喂给Actor一条prompt (这里假设batch_size = 1,所以是1条prompt),让它生成对应的response。
然后,我们再将“prompt + response"送入我们的“奖励-loss”计算体系中去算得最后的loss,用于更新actor。
2.2.2 Reference Model(参考模型)
Reference Model(以下简称Ref模型)一般也用SFT阶段得到的SFT模型做初始化,在训练过程中,它的参数是冻结的。
Ref模型的主要作用是防止Actor”训歪”,那么它具体是怎么做到这一点的呢?
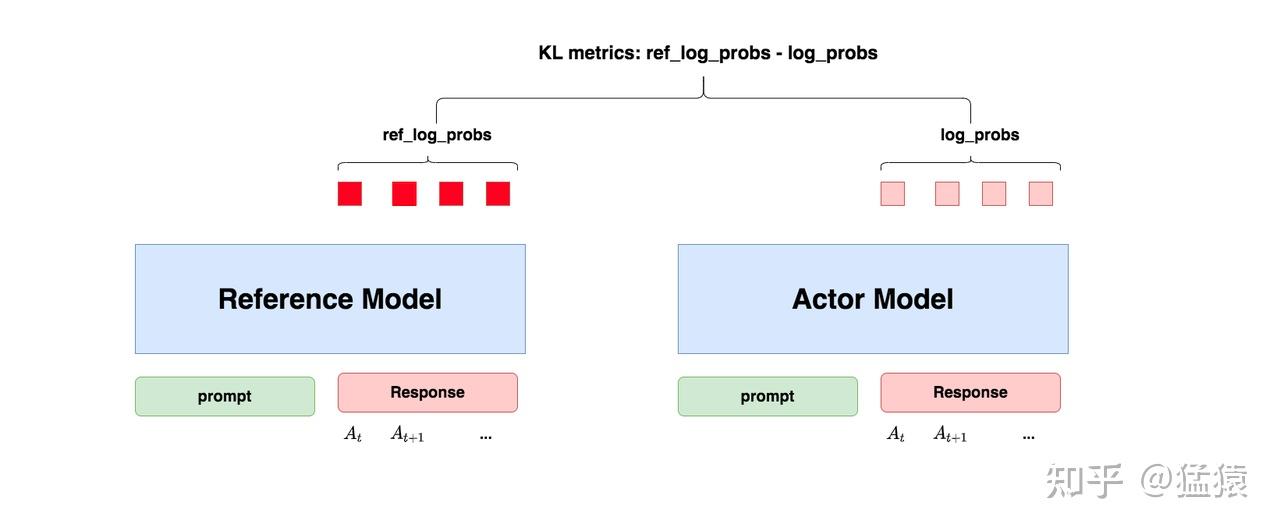
“防止模型训歪”换一个更详细的解释是:我们希望训练出来的Actor模型既能达到符合人类喜好的目的,又尽量让它和SFT模型不要差异太大。
简言之,我们希望两个模型的输出分布尽量相似。那什么指标能用来衡量输出分布的相似度呢?我们自然而然想到了KL散度。
如图所示:
- 对Actor模型,我们喂给它一个prompt,它正常输出对应的response。那么response中每一个token肯定有它对应的 log_prob 结果呀,我们把这样的结果记为log_probs
- 对Ref模型,我们把Actor生成的"prompt + response"喂给它,那么它同样能给出每个token的log_prob结果,我们记其为ref_log_probs
- 那么这两个模型的输出分布相似度就可以用
ref_log_probs - log_probs来衡量,我们可以从两个方面来理解这个公式: - 从直觉上理解,ref_log_probs越高,说明Ref模型对Actor模型输出的肯定性越大。即Ref模型也认为,对于某个 ,输出某个 的概率也很高( )。
- 从KL散度上理解, (当然这里不是严格的等于,只是KL散度的近似),这个值越小意味着两个分布的相似性越高。
这时可以认为Actor模型较Ref模型没有训歪。
(当然这里不是严格的等于,只是KL散度的近似),这个值越小意味着两个分布的相似性越高。
2.2.3 Critic Model(评论家模型)
Critic Model用于预测期望总收益 ,和Actor模型一样,它需要做参数更新。
实践中,Critic Model的设计和初始化方式也有很多种,例如和Actor共享部分参数、从RW阶段的Reward Model初始化而来等等。
我们讲解时,和deepspeed-chat的实现保持一致:从RW阶段的Reward Model初始化而来。
训练 Actor 模型我能理解,但我还是不明白,为什么要单独训练一个Critic模型用于预测收益呢?
这是因为,当我们在前文讨论总收益 (即时 + 未来)时,我们是站在上帝视角的,也就是这个 就是客观存在的、真正的总收益。
但是我们在训练模型时,就没有这个上帝视角加成了,也就是在 时刻,我们给不出客观存在的总收益 ,我们只能训练一个模型去预测它。
所以总结来说,在RLHF中,我们不仅要训练模型生成符合人类喜好的内容的能力(Actor),也要提升模型对人类喜好量化判断的能力(Critic)。这就是Critic模型存在的意义。我们来看看它的大致架构:
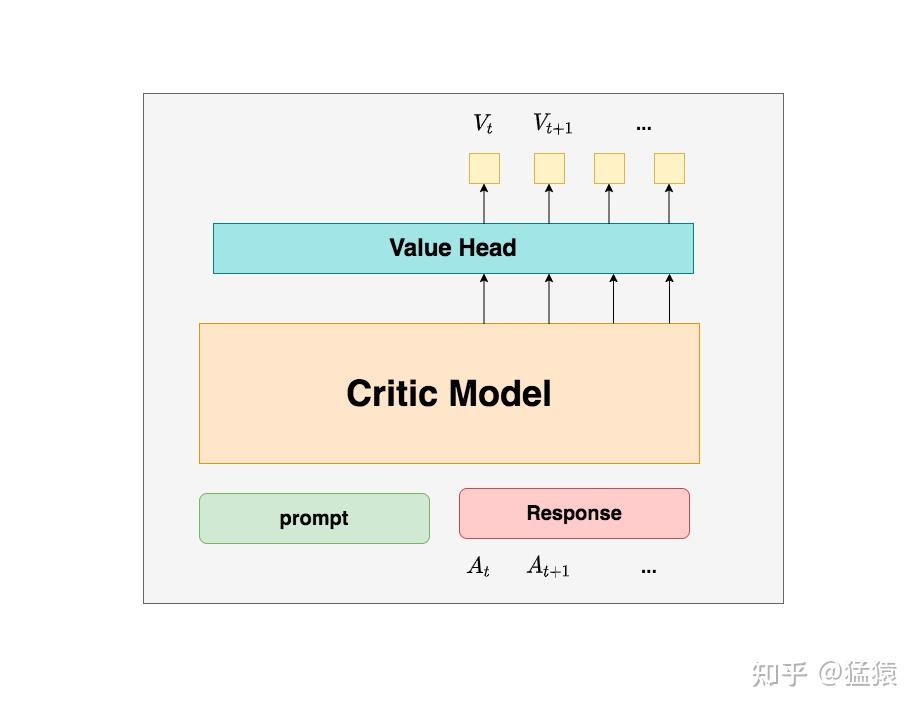
deepspeed-chat 采用了Reward 模型作为它的初始化,所以这里我们也按Reward模型的架构来简单画画它。
你可以简单理解成,Reward/Critic模型和Actor模型的架构是很相似的(毕竟输入都一样)
同时,它在最后一层增加了一个Value Head层,该层是个简单的线形层,用于将原始输出结果映射成单一的 值。
在图中, 表示Critic模型对 时刻及未来(response完成)的收益预估。
2.2.4 Reward Model(奖励模型)
Reward Model用于计算生成token 的即时收益,它就是RW阶段所训练的奖励模型,在RLHF过程中,它的参数是冻结的。
为什么Critic模型要参与训练,而同样是和收益相关的Reward模型的参数就可以冻结呢?
这是因为,Reward模型是站在上帝视角的。这个上帝视角有两层含义:
- 第一点,Reward模型是经过和“估算收益”相关的训练的,因此在RLHF阶段它可以直接被当作一个能产生客观值的模型。
- 第二点,Reward模型代表的含义就是“即时收益”,你的token 已经产生,因此即时收益自然可以立刻算出。
我已经用Critic预测出 了,而这个 包含了“即时”和“未来”的概念,那我还需要代表“即时”的 做什么呢?直接用 不就好了吗?
为了解答这个问题,我们先回顾下前部分中给出的价值函数:
这个函数告诉我们,我们当前可以用两个结果来表示 时刻的总收益:
- 结果1:Critic模型预测的
- 结果2:Reward模型预测的 和critic模型预测的
那么哪一个结果更靠近上帝视角给出的客观值呢?
- 当然是结果2,因为结果1全靠预测,而结果2中的 是事实数据。
我们知道Critic模型也是参与参数更新的,我们可以用
MSE(上帝视角的客观收益 - Critic模型预测的收益)来衡量它的loss。但是上帝视角的客观收益我们是不知道的,只能用已知事实数据去逼近它,所以我们就用 来做近似。这就是 同时存在的意义
Reward 模型和 Critic 模型非常相似,这里我们就只给出架构图,不再做过多的说明。
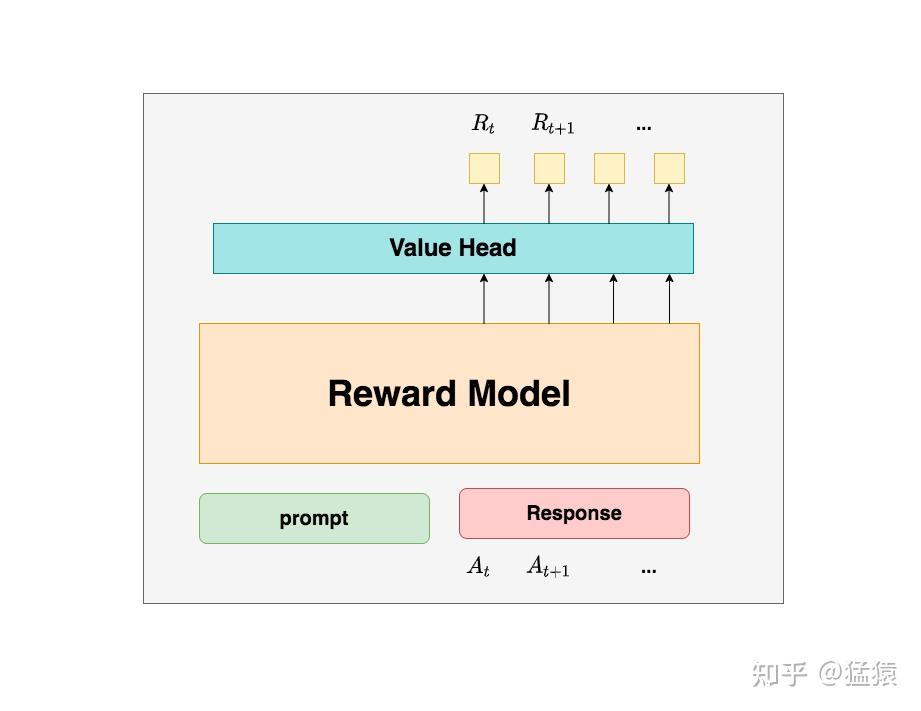
对于大模型输出的每一步而言:
- State:截止到当前的Token序列
- Action:接下来输出的 Token
- 策略函数:LLM本身
有个小问题:Reward 模型只针对完整输出给出一个得分,并不是对每一个Token都会给一个得分。
所以 score 只是给最后一个Token 的,其他所有 Token 的 score 都为 0
由于Reward 可以自己设定,我们可以给每个Token 可以增加一个奖惩项,让他输出的概率分布和基准模型的 KL 散度相关。
3. RLHF 中 PPO 的 loss 计算
在第二部分中,我们知道Actor和Critic模型都会做参数更新,所以我们的loss也分成2个:
- Actor loss:用于评估Actor是否产生了符合人类喜好的结果,将作用于Actor的BWD上。
- Critic loss:用于评估Critic是否正确预测了人类的喜好,将作用于Critic的BWD上。
3.1 Actor loss
3.1.1 直观设计
先忘掉上一篇中关于PPO Loss 的推导,我们先来看一个直观的loss设计方式:
用大模型的视角重现上一篇中的推导
- Actor 接收到当前上文 ,产出 token ( )
- Critic 根据 ,产出对总收益的预测
- 那么Actor loss可以设计为:
我们希望minimize这个actor_loss。
一句话总结:这个 loss 设计的含义是,对上文 而言,如果 token 产生的收益较高,那就增大它出现的概率,否则降低它出现的概率。
3.1.1 引入优势(动作价值 - 状态价值)
是critic 模型对总收益的预测,只有状态价值。
有点反常识,怎么能不考虑这一步的 Action 呢?
根据上一篇,引入优势(Advantage)
对NLP任务来说,如果 Critic 对 的总收益预测为 ,但实际执行 后的总收益是 ,我们就定义优势为:
actor loss 此时成为了:
3.1.2 重新设计
优势函数里面有一项为 ,模型的 Reword 如何计算:

针对每个当前Token,大模型会通过 LLM head 输出字典里的每个 Token 作为输出的概率。
在同样的State 下,训练模型如果跟基准模型概率分布不一致,就会收到惩罚。分布越不一致,惩罚越大,有一个调整系数控制,默认为


训练模型在 时刻做出每一个Action(输出每一个Token)的 总Reward 就等于它输出的概率分布相对于基准模型输出的概率分布 KL 散度 再加上 Reward score。
非 时刻,就只有输出的概率分布相对于基准模型输出的概率分布 KL 散度
基于这些,上面这个对 的设计可理解成:
- 当时 ,我们更加关心Actor是否有在Ref的约束下生产token
- 当 时,我们不仅关心Actor是否遵从了Ref的约束,也关心真正的即时收益
3.1.3 重新设计优势
好,再总结一下,目前为止我们的actor_loss为:
其中:
同时,我们对 进行来改造,使其能够衡量Actor模型是否遵从了Ref模型的约束。
现在我们把改造焦点放在 上,回想一下,既然对于收益而言,分为即时和未来,那么对于优势而言,是不是也能引入对未来优势的考量呢?
这样,我们就可以把 Advt 改写成如下形式:
这个代表未来优势的 ,我要怎么算呢?
注意到,对于最后一个时刻 ,它的未来收益()和未来优势()都是0,也就是:
,这是可以直接算出来的。而有了,我们不就能从后往前,通过动态规划的方法,把所有时刻的优势都依次算出来了吗?
这个东西长的好像上一篇中学到的 GAE!
在【强化学习基础中】得到的 GAE 计算公式:
GAE 的迭代表达方式为(更适合编程实现):
其中, 也是一个常量,可将其理解为权衡因子,直觉上看它控制了在计算当前优势时对未来优势的考量。(从强化学习的角度上,它控制了优势估计的方差和偏差)
3.1.4 PPO-epoch: 引入新约束
总结一下,目前为止我们的actor_loss为:
其中,
同时:
- 我们已经对 进行了改造,使其能够衡量 Actor 模型是否遵从了 Ref 模型的约束。
- 我们已经对进行优势进行了改造,引入了GAR,使其不仅考虑了当前时刻的优势,还考虑了未来的优势。
基于这些改造,我们重新理一遍RLHF-PPO的训练过程。
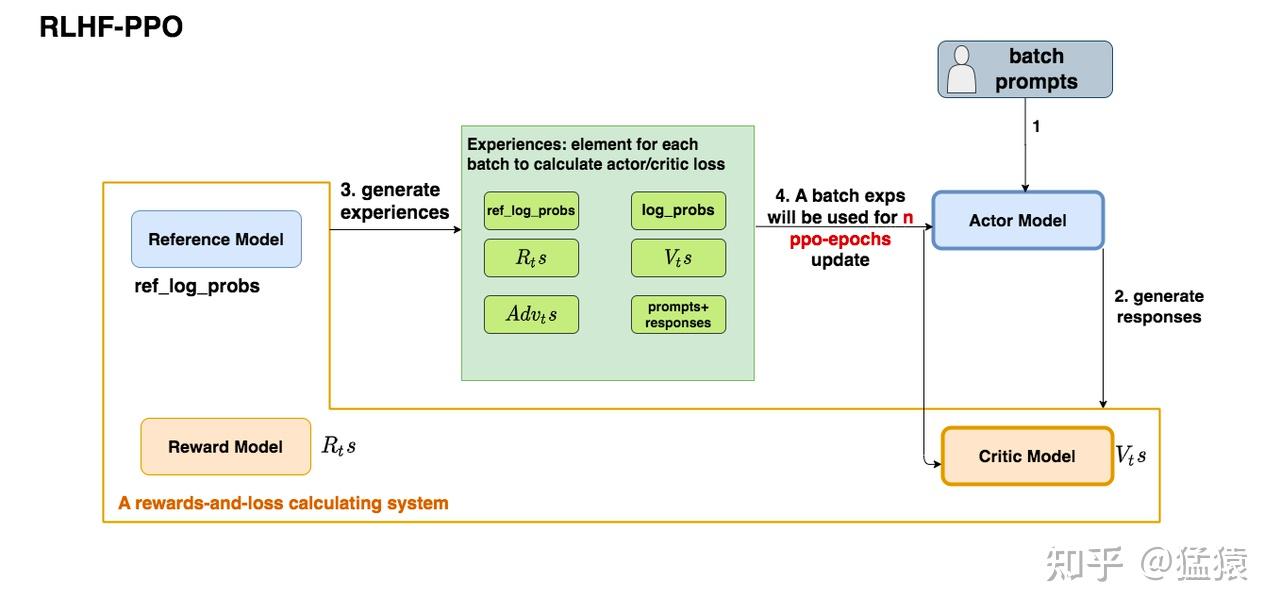
- 第一步,我们准备一个batch的prompts
- 第二步,我们将这个batch的prompts喂给Actor模型,让它生成对应的responses
- 第三步,我们把prompt+responses喂给我们的Critic/Reward/Reference模型,让它生成用于计算actor/critic loss的数据,按照强化学习的术语,我们称这些数据为经验(experiences)。critic loss我们将在后文做详细讲解,目前我们只把目光聚焦到actor loss上
- 第四步,我们根据这些经验,实际计算出actor/critic loss,然后更新Actor和Critic模型
这些步骤都很符合直觉,但是细心的你肯定发现了,文字描述中的第四步和图例中的第四步有差异:图中说,这一个batch的经验值将被用于n次模型更新,这是什么意思呢?
我们知道,在强化学习中,收集一个batch的经验是非常耗时的。对应到我们RLHF的例子中,收集一次经验,它要等四个模型做完推理才可以,正是因此,一个batch的经验,只用于计算1次loss,更新1次Actor和Critic模型,好像有点太浪费了。
所以,我们自然而然想到,1个batch的经验,能不能用来计算 ppo-epochs 次 loss,更新 ppo-epochs 次 Actor 和 Critic 模型?简单写一下伪代码,我们想要:
而如果我们想让一个batch的经验值被重复使用 ppo_epochs 次,等价于我们想要Actor在这个过程中,模拟和环境交互 ppo_epochs 次。举个例子:
- 如果1个batch的经验值只使用1次,那么在本次更新完后,Actor就吃新的batch,正常和环境交互,产出新的经验值
- 但如果1个batch的经验值被使用ppo_epochs次,在这ppo_epochs中,Actor是不吃任何新数据,不做任何交互的,所以我们只能让Actor“模拟”一下和环境交互的过程,吐出一些新数据出来。
那怎么让Actor模拟呢?很简单,让它观察一下之前的数据长什么样,让它依葫芦画瓢,不就行了吗?
我们假设最开始吃batch,吐出经验的 actor 叫 ,而在伪代码中,每次做完 ppo_epochs 而更新的 actor 叫 ,那么我们只要尽量保证每次更新后的
能模仿最开始的那个,不就行了吗?
两个分布,通过什么方法让它们相近!那当然是KL散度!所以,再回到我们的actor_loss上来,它现在就可被改进成:
其中,
其中, 表示真正吃了batch,产出经验值的Actor; 表示ppo_epochs中实时迭代更新的Actor,它在模仿 的行为。
所以这个公式从直觉上也可以理解成:在Actor想通过模拟交互的方式,使用一个batch的经验值更新自己时,它需要收到真正吃到batch的那个时刻的Actor的约束,这样才能在有效利用batch,提升训练速度的基础上,保持训练的稳定。
但是,谨慎的你可能此时又有新的担心了:
虽然我们在更新Actor的过程中用 做了约束,但如果
的约束能力不够,比如说 还是超出了可接受的范围,那怎么办?
很简单,那就剪裁(clip)它吧!
⇒
其中:
- 我们已经对 进行了改造,使其能够衡量Actor模型是否遵从了Ref模型的约束
- 我们已经对 进行改造,引入了GAE,使其不仅考虑了当前时刻的优势,还考虑了未来的优势。
- 我们重复利用了1个batch的数据,使本来只能被用来做1次模型更新的它现在能被用来做ppo_epochs次模型更新。我们使用真正吃了batch,产出经验值的那个时刻的Actor分布来约束ppo_epochs中更新的Actor分布
- 我们考虑了剪裁机制(clip),在ppo_epochs次更新中,一旦Actor的更新幅度超过我们的控制范围,则不对它进行参数更新。
3.2 Critic loss
需要首先知道状态价值的 label 是什么,其实就是实际收益,生成每个Token状态价值的label 有三种方式:
- 蒙特卡洛法(方差太大):整个问答序列为一次随机采样,将当前 Token 后面的Reword 的衰减累加值作为label。因为 label 是一次随机采样得到的,所以方差很大
- 时序差分法(偏差太大):只采样一步,采样到这一步的 Reward 加上下一步的状态价值乘上衰减因子
- 广义优势法(平衡方差和偏差):GAE优势函数加上当前步的状态价值的估计值
- :实际收益
GAE 优势函数表示每一步状态做出当前动作的期望回报减去当前状态的期望回报
因为 GAE 计算当前动作的期望回报时考虑了一步采样,两步采样到多步采样,所以平衡了偏差和方差
我们用 ”预估收益“ 和 实际收益” 的 MSE 来当做 Loss。
我们原始的预估收益为 。
类比于Actor,Critic模型在ppo_epochs的过程中也是不断更新的。所以这个可以理解成是 ,
也就是真正吃了batch,参与产出经验的那个时候的Critic产出的收益预测结果。
我们同样想用旧模型去约束新模型,但对于Critic我们采用的约束策略就比较简单了,我们直接看代码,从中可以看出,我们用老 设计了了一个变动范围,然后用这个变动范围去约束新
那么最终我们就取实际收益和预估收益的MSE做为loss就好,这里注意,计算实际收益时都是老Critic(真正吃了batch的那个)产出的结果,而预估收益是随着ppo_epochs而变动的。
代码如下:
4.完整流程
以下针对 Batch Size 为 8 的场景,详细拆解 PPO (Proximal Policy Optimization) 与 GRPO (Group Relative Policy Optimization) 在 RLHF 全流程中的输入输出、核心计算逻辑及 Loss 代入过程。
这里沿用假设:上下文总长 ,Prompt 长度 ,Response 长度 。
1. RLHF (基于 PPO 的标准流程)
场景设定:Batch Size = 8 (指 8 个独立的 Prompts)。
核心逻辑:Actor-Critic 架构,需要 4 个模型(Actor, Critic, Ref, Reward)。
阶段 1:生成 (Generation) - Experience Collection
- 输入:Prompts
[8, L_prompt]。
- 处理:使用 vLLM 进行自回归生成。
- 输出:Sequences
[8, L](Prompt + Response)。此时只拿到 Token IDs。
阶段 2:准备 (Preparation) - 优势估算与回报计算
此阶段目标是构建用于 PPO 更新的“经验池” (Buffer),并计算 GAE (Generalized Advantage Estimation)。
- 基础推理 (Inference):
- 保存当前策略网络 对生成的每个 Token 的对数概率。
- 用于后续计算 Importance Sampling Ratio (重要性采样比率) 。
- 这里的 action 指“第 个生成的 response token”。
- state 指“生成第 个 response token 之前看到的上下文(prompt + 已生成到 )”。
- 因此 ,并且后面的 也应当对应同一个 。
- 实现里经常需要做 shift(例如用
logits[:, :-1]对齐tokens[:, 1:]),最终确保:每个位置 t 的 logprob/value 都对应“采样该 token 之前的 state”。 - 冻结的参考模型(通常是 SFT 模型),用于计算 KL 散度,防止策略跑偏。
- 对生成的完整句子进行打分,仅在序列结束位置 () 产生标量值。
- 估计当前 Token 及其之前上下文组成的 State () 的预期未来回报 。
- 通常包含一个 Bootstrap Value (最后一步之后的状态价值,通常设为 0)。
- 实际 batch 内每条 response 长度不同,
L_resp往往是该 batch 的最大长度,短序列会被 PAD 补齐。 - 因此需要额外保存
response_mask / padding_mask(或loss_mask): - 只在真实 response token 位置为 1,在 prompt 和 padding 位置为 0。
- 后续计算
Rewards/Advantages/Returns以及 PPO 的 actor/critic loss 时,都必须对 padding 部分 mask 掉,否则会把 PAD 位置当成有效 token 污染统计量与梯度。
Actor: 计算 Old_Log_Probs [8, L_resp]。
✅补充 A:对齐(shift)约定必须写清楚
Ref Model: 计算 Ref_Log_Probs [8, L_resp]。
Reward Model: 计算最终评分 Scores [8] (通常只针对 EOS token)。
Critic: 计算状态价值 Values [8, L_resp]。
✅补充 B:变长序列与 mask(训练/计算时必须用)
- 构建稠密奖励 (Dense Rewards) : PPO 需要每一步的奖励。
- 对于中间 Token (): (即 KL 散度惩罚)。
- 对于最后一个 Token ():。
- 结果:
Rewards[8, L_resp]。 - 这里使用的 KL shaping 是 token-level 的:,在 rollout 阶段就把惩罚折进 dense reward。
- PPO 更新时仍会重新计算 得到
New_Log_Probs用于 ratio;如果实现里还额外加显式 KL(或 adaptive KL controller),那通常约束的是 new policy vs ref。 - 因此你这一步可以理解为:buffer 中固定的 reward shaping(old vs ref 的近似 KL),用于稳定训练、防止策略偏离参考模型。
✅补充 C:KL shaping 的口径说明(rollout old vs ref / update new vs ref)
- 计算 GAE (优势函数) : 利用 TD Error () 递归计算。
- 计算 (最后一步 )。
- 时刻:Actor 写了一半的句子。
- :Critic 看了这一半句子后说:“我觉得照这个趋势写下去,最后这句话能得 0.8 分(满分 1 分)。”
- 递归计算 。
- (最后一步): (最后一步没有未来优势,优势纯粹来自当前的 TD Error)。
- (倒数第二步): (当前的优势 = 当前的误差 + 打折后的未来优势)。
- (任意一步):
- (Discount Factor):关注长远利益的程度。
- (GAE Parameter):平衡偏差 (Bias) 与方差 (Variance)。
- : (高偏差,低方差)
- : (Monte Carlo,无偏差,高方差)
- 结果:
Advantages[8, L_resp]。
Critic 模型对当前局势的 “打分” 或 “预判”:
递归逻辑展开:
参数含义:
- 计算回报 (Returns) (用于 Critic 训练目标):
- 。
- Critic 的训练目标是最小化 MSE Loss:
- 这实际上是让 Critic 去拟合“当前价值预估 + 实际计算出的优势”,即修正后的真实回报。
- 结果:
Returns[8, L_resp]。
最终 Buffer 内容:Sequences, Old_Log_Probs, Advantages, Returns, Values。
阶段 3:学习 (Learning) - 梯度更新
输入:从 Buffer 中采样的 Mini-batch (例如 8 条数据)。
计算过程:
- Actor 更新 (Policy Loss):
- 前向传播:Actor 对 Sequences 再次计算
New_Log_Probs[8, L_resp]。 - 计算概率比率 (Ratio):
- 代入 Loss (Clipped Surrogate Objective):
- 最终 Actor Loss: (通常取负号以最小化)。
在 PPO 训练循环的第一个 Step(第一轮迭代) 时,
New_Log_Probs 的数值确实严格等于 Old_Log_Probs(在浮点误差允许范围内)。
但我们依然需要重新计算它,且这背后有 3 个至关重要的原因:
1. 建立梯度计算图 (Computational Graph) —— 最核心原因
这是深度学习框架(如 PyTorch)的机制决定的。
• Old_Log_Probs:这仅仅是存放在显存里的一堆 “死数字”(Tensor with
.detach())。它切断了反向传播的链路,没有任何梯度信息。它代表的是“过去的历史”。
• New_Log_Probs:这是通过当前模型 Actor(Sequences) 刚刚算出来的。它是 “活的 Tensor”,带有 grad_fn(梯度函数)。
为什么必须重算?
如果我们直接在 Loss 里面写 Ratio = 1.0,那么 Loss 就是一个常数,反向传播时梯度为 0,模型参数根本无法更新。
为了更新模型,Loss 函数中必须包含 当前模型的输出节点。
即:
只有这样,对 Loss 求导时,梯度才能顺着 传回到模型的权重(Weights)上。
2. PPO 的多 Epoch 迭代 (Multi-Epoch Updates)
PPO 是一个 Off-Policy (或者说 On-Policy 变体) 算法,它的特点是:采一次样,利用很多次。
通常 PPO 的超参数中有一个
update_epochs (比如设为 4)。
• Epoch 1: New Old。Ratio 1。模型根据优势 进行第一次微调。参数 变了。
• Epoch 2: 此时模型参数 已经更新了一次。当我们再次把同样的 Sequences 喂给 Actor 时,算出来的 New_Log_Probs 就 不再等于 Old_Log_Probs 了。Ratio 开始偏离 1。
• Epoch 3...: 随着参数更新,Ratio 偏离越远,PPO 的 clip 机制(截断 )开始发挥作用,防止模型更新过头。
如果第一步不重算,后续的 Epoch 也就无法基于更新后的参数计算新的概率比率了。
3. Mini-batch 的影响
虽然你采集了 Batch=8 的数据,但在训练时,我们可能会把这 8 条数据再拆分成更小的 Mini-batch(比如 size=2)进行更新。
• 第 1 个 Mini-batch:
New = Old。更新模型。
• 第 2 个 Mini-batch: 此时模型已经被第 1 个 Mini-batch 更新过了。所以即使是同一个大 Batch 里的数据,New 也不再等于 Old。- Critic 更新 (Value Loss):
- 前向传播:Critic 对 Sequences 再次计算
New_Values[8, L_resp]。 - 代入 Loss (MSE): (注:通常也会对 New_Values 进行 clip 操作以防止更新幅度过大)
- 参数更新:
- Total Loss = 。
- 反向传播并
optimizer.step()。
2. GRPO (Group Relative Policy Optimization)
场景设定:Batch Size = 8 (指 1 个 Prompt 生成了 8 个回复,Group Size=8)。
核心逻辑:移除 Critic 模型,利用“组内相对优势”代替价值估计,大幅节省显存。
阶段 1:生成 (Generation)
- 输入:Prompts
[8, L_prompt](相同的 Prompt 重复 8 次)。
- 处理:vLLM 设置
temperature > 0.7进行多样化采样。
- 输出:Sequences
[8, L](8 个不同的 Response)。
阶段 2:准备 (Preparation) - 组内优势计算
不需要 Critic 估算 ,直接基于结果统计。
- 基础推理:
- Ref Model: 计算
Ref_Log_Probs[8, L_resp]。 - Actor: 计算
Old_Log_Probs[8, L_resp](用于后续 Ratio 计算)。 - Reward Model: 计算
Scores[8],即 。
- 组内归一化 (Group Normalization): 直接计算这组 Reward 的相对优势。
- 均值:
- 标准差:
- 优势计算:。
- 广播:将标量 广播到该序列的所有 Token 位置,即每个 Token 的优势都是该序列的最终得分优势。
- 结果:
Advantages[8, L_resp](每行的值都相同,等于该行的 )。
阶段 3:学习 (Learning)
只更新 Actor,Loss 公式包含 KL 正则项。
输入:准备好的 8 条数据及归一化后的
Advantages。- Actor 前向传播:
- 对 Sequences 计算
New_Log_Probs[8, L_resp]。
- 计算 KL 散度 (Per Token):
- (注:这是 Schulman 的近似 KL,或者直接用 )
- 计算概率比率 (Ratio) (可选,若单次迭代可简化):
- 如果只做一次更新 step,Old 与 New 相同,Ratio 为 1,则主要靠梯度方向指导。但标准实现通常保留 Importance Sampling 以支持多 Epoch 更新。
- 代入 GRPO Loss: DeepSeekMath 或 GRPO 的核心 Loss 如下:
- 项 1 (Policy Gradient): 。试图增加优势为正 () 的样本的生成概率。
- 项 2 (KL Regularization): 。约束模型不要偏离参考模型太远。
- 注意:GRPO 将 KL 直接放入 Loss 函数中作为正则项,而不是像 PPO 那样作为 Reward 的一部分。
- 输出:反向传播 Loss,更新 Actor 权重。
- 作者:SimonSun
- 链接:https://simonsun.xyz//article/llm-8
- 声明:本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。
相关文章


